|
|
|
|
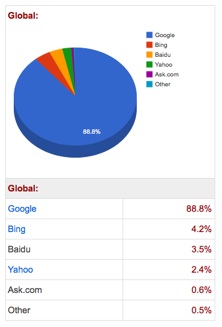
Когда мы говорим о самой популярной операционной системе в общемировом масштабе мы подразумеваем Google – и эта известность неслучайна. Несмотря на то, что Google не является первопроходцем среди поисковых систем Интернета. У него было достаточно большое количество предшественников, известных и не очень; некоторые из них существуют по сей день. Однако по доле на рынке среди них Google нет равных – по данным американской компании Karma Snack, занимающейся исследованиями интернет-маркетинга, этот поисковик занимает уверенное первое место – более 80% рынка [1]:
В чем секрет такой популярности Google, при том, что ни единой конкурирующей поисковой системы ни разу не удалось сместить ее с этой вершины? Преимущества Google заключаются в удобстве использования и в дополнительных функциях, упрощающих и оптимизирующих поиск, а значит, секрет успеха находится глубже, но чём – в технических аспектах этой поисковой системы или в особенностях организации ее процесса поиска?
Некоторые инструментальные характеристики и технические особенности поисковой системы Google Чтобы понять это, следует обратить внимание в первую очередь на технические характеристики Google. Выше речь уже шла об особенностях информационного поиска, которыми занимались Ларри Пейдж и Сергей Брин в процессе создания своего детища: здесь же эти особенности и реализация их в составе Google будет рассмотрена более подробно. Но для понимания технической уникальности Google как составляющего компонента успеха этой поисковой системы, следует первоначально разобраться в том, как работают поисковые системы в целом, тогда на общем примере будет легче разобраться в особенностях Google. Всякая поисковая система состоит из нескольких основных взаимосвязанных компонентов[2]:
Модуль сканирования состоит из программ, основным предназначением которых является сканирование страниц на ссылки и занесение их в базу данных поисковой системы. Программ таких три, их еще именуют роботами или просто «ботами»:
Страницы, посещенные роботами, хранятся в базе данных поисковой системы, из которой можно легко получить доступ к любой странице для последующего взаимодействия с ней. Модуль индексирования добавляет в базу данных информацию о той или иной странице – ключевые слова, изображения, ссылки, по которым страница доступна и т.п. Модуль поиска берет своей целью получение и обработку запросов пользователей, для чего обращается к базе данных. Поиск ведется не только по индексу, но и непосредственно по документам в базе данных [3]. И, наконец, модуль ранжирования сортирует страницы по релевантности, то есть, упорядочивает их так, чтобы первыми в результатах поиска оказывались наиболее соответствующие запросам пользователей страницы. Такая архитектура, привычная для большинства поисковых систем, тем не менее, оставляет нерешенным большое количество проблем, связанных с поиском данных. Во-первых, ранжирование по анализу идентичности текста страницы и текста запроса оставляет лазейку администраторам сайтов, в желании продвинуть свои страницы активно использующих такое понятие, как поисковый спам. Интернет-энциклопедия Wikipedia дает определение поискового спама как «сайтов и страниц в Интернете, созданных с целью манипуляции результатами поиска в поисковых машинах — в конечном счете, для обмана пользователя» [4]. При использовании подобного рода махинаций администратор мог запросто поднять рейтинг сайта, заполняя текстовое содержимое ключевыми словами без изменений [2] или просто добавляя в HTML-код страницы наиболее популярные поисковые запросы, хотя никакой информации по ним страница могла и не содержать. Это породило еще в эпоху Web 1.0 даже шуточные советы добавлять в список ключевых слов страницы слово «порно» для того, чтобы наверняка увеличить посещаемость и популярность ресурса. С этой проблемой также связана угроза так называемых дорвеев (от англ. doorway – дверной проем, портал) - веб-страниц, специально оптимизированных под один или несколько поисковых запросов с единственной целью их (страниц) попадания на высокие места в результатах поиска по этим запросам [5]. Кроме того, отдельным вопросом остается так называемая «глубокая паутина» (англ. Invisible web) – страницы, не индексируемые поисковыми системами. В «глубокую паутину» входят, например, веб-страницы, динамически генерируемые по запросам к онлайн-базам данных [6]. Эта информация остается недоступной для поискового робота, неспособного в режиме реального времени правильно заполнить форму значениями (другими словами, сформировать запрос к базе данных) [7]. Также к этому понятию относятся сайты, доступ к которым открыт только для зарегистрированных пользователей. Таким образом, значительная часть Всемирной паутины оказывается скрыта от поисковых роботов, находится «на глубине» [7]. Борьба с «глубокой паутиной» и поисковым спамом – это отдельная проблема, над решением которой специалисты работают уже не первый год. Однако в начале нового века, на заре своего существования, Google предложил в качестве средства борьбы с поисковым спамом и организацией использование так называемого «индекса цитирования» - показателя поисковой системы, вычисляемый на основе числа ссылок на данный ресурс с других ресурсов Интернета [8]. На основе индекса цитирования Google проводит процедуру ссылочного ранжирования найденных страниц, сортируя их по релевантности, т.е. по семантическому соответствию поискового запроса и поискового образа документа [9]. Google был первой поисковой системой, в механизме поиска которой был задействован этот метод [10]. Алгоритм ссылочного ранжирования, используемый в Google, получил название PageRank (дословно с английского языка это слово может быть переведено как «рейтинг страницы», однако компания Google Inc. связывает слово Page в названии алгоритма не с английским словом «страница», а с именем одного из основателей, Лэрри Пейджа (англ. Larry Page) [11]. Как уже говорилось выше, в состав модуля сканирования любой поисковой системы входят несколько программ-роботов. Одна из них, crawler, или путешествующий паук, анализирует не только содержимое самой страницы, но и всех ссылок в ней и тех страниц, на которые эти ссылки выводят. Принцип действия Google PageRank заключается в анализе совокупности группы объединенных этими гиперссылками документов. В этой совокупности каждому отдельному документу или странице присваивается свой собственный числовой код – коэффициент «важности» среди других страниц. Собственно PageRank - это и есть показатель степени важности каждой отдельно взятой страницы, расположенной в Интернете [12]. Показатель этот высчитывается путем расчета уравнения с более 500 переменными и 2 миллиардами терминов [13]. Точная формула расчета этого показателя является ноу-хау самой компании Google, но в упрощенном варианте это уравнение выглядит так: PR(Y) = (1 - Kz) + Kz*PR(X1)/L(X1) + Kz*PR(X2)/L(X2) + … + Kz*PR(Xn)/L(Xn), где: PR(Y) - PageRank страницы Y; Kz - коэффициент затухания (иными словами, чем больше на странице ссылок, тем меньше PageRank она по ним передаёт другим страницам); PR(X1-n) - PageRank страниц, которые ссылаются на страницу Y; L(X) - количество ссылок на странице X [12]. При этом различают два вида PageRank: тулбарный и истинный PageRank, причем первый из них становится виден при установке Google Toolbar – специальной надстройки для программы-браузера, - и показывает приблизительное значение важности страницы от 0 до 10, а второй – это и есть тот самый показатель, который используется поисковой системой при ссылочном ранжировании. Однако необходимо подчеркнуть, что упорядочивание ссылок по релевантности происходит при учете не только показателя PageRank, но и других деталей: заголовка статьи (title), текста ссылок на данную страницу, ключевых слов и т.п [12]. Немаловажен также факт того, что человек, т.е. пользователь, вообще не принимает участия в обработке результатов PageRank. Формирование результатов, определение показателя важности и процесс ссылочного ранжирования полностью автоматизированы, для определения значимости страницы используется коллективный интеллект Интернета[13]. Это и привлекает пользователей к Google – объективность информации и действительно наиболее релевантные данные в числе самых первых результатов поиска, за нахождение в которых не надо платить [13]. В широком смысле, концепция PageRank воплощает в себе один из признаков Web 2.0, описанных Тимом О’Рейли еще в 2005 году в его статье «What Is Web 2.0», более того – сам автор этой статьи сообщает о PageRank как о том, что «прорыв Google в поиске, в мгновение ока сделавший компанию безоговорочным лидером рынка, был основан на PageRank, методе, использующем для обеспечения наилучших результатов прежде всего ссылочную структуру веба, а не характеристики проиндексированных документов [14]». С алгоритмом PageRank в Google неразрывно связан процесс анализа сопоставления гипертекста. Этот процесс заключается в глубоком сканировании текста группы страниц. Кроме непосредственно содержания текста (которым могут манипулировать издатели сайта с помощью метатегов, тем самым затрудняя поиск), Google анализирует также такие факторы, как шрифты, подразделы и точное местоположение каждого слова. На основе полученных в результате этой процедуры данных, а также на основе анализа соседних веб-страниц, поисковая система обеспечивает результатам поиска наибольшую релевантность [13]. Однако алгоритм Google PageRank не является чем-то неизменным – с момента запуска поисковой системы Google в марте 1998 года он претерпел немало изменений. Каждый год из 15 лет существования поисковика Google нес сразу несколько обновлений для PageRank, многие из которых представляли собой существенные дорабортки и изменения этого алгоритма, попортившие немало крови специалистам по поисковой оптимизации. Формат данной статьи не позволит разобрать все эти обновления – тем более что в большинстве своем они были незначительными, - поэтому стоит остановиться лишь на самых крупных и радикальных из них. PageRank сегодня является лишь одним из многих показателей, по которым оценивается релевантность страницы при ее индексации в Google. Другим значением, формирующим результаты поисковой выдачи, стала так называемая тематическая релевантность страницы. Алгоритм PageRank определяет ценность страницы за счет предельно полного количества ссылок на нее, не делая при этом различий в тематическом содержании страниц, на которых размещены эти ссылки. Исправить этот недостаток был призван разработанный уроженцем Индии, доктором философских наук Кришной Баратом (англ. Krishna Bharat) алгоритм Hilltop, определяющий «авторитетность» web-страницы по отношению к конкретно заданному запросу или поисковому термину [15]. «Тематическая релевантность» - определение, введенное самим Баратом; оно обозначает количество сайтов со схожей тематикой, ссылающихся на ту или иную страницу. Подобные сайты со схожей тематикой Барат называет «экспертными сайтами» (англ. Expert pages) [16], а ссылки от таких экспертных документов на целевые документы определяет как их «показатель авторитетности» [15]. Алгоритм Hilltop был запатентован Google в 2001 году. Процедура индексации результатов сканирования по этому алгоритму включала в себя три этапа:
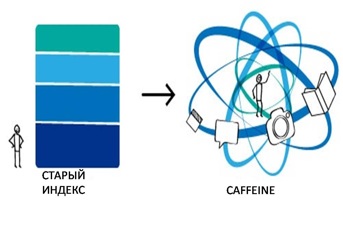
При этом очистка результатов поиска от ссылок с дочерних сайтов происходила следующим образом: из полученных данных изымались ссылки с сайтов, располагающихся на одном и том же домене (например, (www.ibm.com, www.ibm.com/us/, products.ibm.com и т.п.), на его под-доменах и доменах второго уровня (например, www.ibm.com, www.ibm.co.uk, www.ibm.co.jp) или на сайтах с соседними IP-адресами, определяемыми по схожести первых восьми цифр номера IP [17]. У алгоритма Hilltop были также свои недостатки. Они связаны с определением «экспертных» сайтов и отношением к ним системы. В частности, Hilltop основывался на предположении, что каждый «экспертный» документ, который он находит, будет беспристрастен, свободен от спама и манипуляций [15]. Не учтено было также, что использование Hilltop требовало достаточно внушительных аппаратных мощностей на серверах, что могло вызвать затруднения в процессе индексации и позволяло проводить эту процедуру не чаще чем раз в месяц. Кроме того, внедрение Hilltop неизбежно должно было сказаться на информации, располагающейся на исключаемых из зоны его анализа «дочерних» сайтах. Так и случилось 16 ноября 2003 года, когда в Google было внедрено массивное обновление, получившее название «Florida» - по имени знаменитого американского урагана[18]. После этого обновления в результатах запросов Google произошел серьезный сдвиг, который затронул тысячи веб-страниц, заставив их упасть на несколько десятков позиций в результатах поиска по ключевым словам, на продвижение через которые их администраторы в основном рассчитывали. На места этих страниц при этом пришли сайты с содержимым, весьма туманно напоминающим исходный запрос [18]. По поводу причины подобного сбоя, равно как и причины столь революционного обновления, у аудитории до сих пор нет четкого ответа, хотя одно из самых значительных предположений свидетельствует о том, что причиной этому стало внедрение алгоритма Hilltop [18]. Как бы то ни было, объединение алгоритмов PageRank и Hilltop принесло Google ощутимые результаты, состав комбинацию, высокоустойчивую против махинаций с результатами поиска [15]. Точная формула, по которой производится ссылочное ранжирование в Google сегодня, находится под строжайшим секретом, но в упрощенной форме ее можно представить в следующем виде: {(1-d)+a (RS)} * {(1-e)+b (PR * fb)} * {(1-f)+c (LS)}, где: RS – RelevanceScore, или показатель релевантности. Этот показатель основан на ключевых словах, появляющихся в заголовке, мета-тегах, подзаголовках, теле текста, и т.п.; PR – показатель PageRank, высчитываемый по одноименому алгоритму Google; LS – показатель LocalScore, высчитываемый по алгоритму Hilltop; A, B, C, D, E, F – переменные, используемые для тонкой подстройки результата, причем a, b, и с – это так называемые показатели веса страницы (Tweak Weight Controls), а d, e и f - показатели демпфирующего контроля (Dampfer Controls) [15]. Следующим значимым обновлением поискового механизма Google стал алгоритм Google Caffeine, объявление о завершении работы над которым появилось в официальном блоге Google 9 июня 2010 года. Еще до этого новый алгоритм был предложен рядовым пользователям для бета-тестирования: в августе 2009 года было опубликовано объявление о начале испытаний Caffeine, которые закончились в ноябре [19].
«Caffeine на 50% «свежее» предыдущего индекса и представляет собой самую большую коллекцию веб-страниц за нашу историю. Что бы вы ни искали — новости, сообщения в блогах или на форумах, — нужные вам страницы теперь еще быстрее попадут в наш индекс, а вы сможете их быстрее найти,» - сообщает в этом блоге один из разработчиков этой системы Кэрри Грин [20]. Действительно, Caffeine предложил пользователям широкий ассортимент нововведений. Обновление коснулось не только алгоритма поиска, но и всей поисковой системы, которая расширила результаты выдач по запросам за счет добавления в результаты поиска мультимедийных материалов (фотографий и видеофайлов), а также за счет поиска по социальным сетям, таким, как Facebook и Twitter. Введение Caffeine потребовало полной переработки файловой системы Google, существующей без изменений с последнего десятилетия прошлого века: на место старой GFS (Google File System) пришла система GFS2, основным принципом работы которой стала высокая скорость отклика на пользовательский запрос. Ранее этот принцип приносился в жертву обеспечению высокой пропускной способности [21]. Введение Caffeine и обновление файловой системы обусловило существование поисковой системы Google в том виде, в котором она известна сегодня, и сделало возможным внедрение таких функций, как, например, Живой поиск, о котором речь пойдет в следующем разделе. Одной из особенностей Caffeine в области ранжирования поисковых результатов стал учет скорости загрузки индексируемых страниц (более медленные сайты после введения новых алгоритмов потеряли места в поисковых выдачах) [22]. Кроме того, была проведена дальнейшая оптимизация алгоритмов ссылочного ранжирования, включающая в себя усовершенствования оценки как авторитетности, так и цитируемости документа. В новой системе учитывается и возраст домена, на котором располагается индексируемый сайт – предпочтение здесь отдается более старым доменам [22]. 24 февраля 2011 года был запущен очередной масштабный поисковый алгоритм – Google Panda, сразу после своего появления (согласно отзывам в многочисленных блогах SEO-специалистов) значительно изменивший позиции многих сайтов в индексе Google. Причиной этому были изменившиеся (и значительно ужесточившиеся) критерии индексации сайтов – благодаря введению нового алгоритма Google стал учитывать впридачу к авторитетности ресурсов, скорости их загрузки и распространенности упоминаний о них в Сети еще и качество размещаемого на них контента. Показатель качества Panda высчитывает с учетом большого количества факторов, среди которых:
Полный список факторов, влияющих на ранжирование сайтов согласно алгоритму Panda, составляет больше сотни одновременно анализируемых параметров [23]. Цель же введения нового алгоритма, согласно официальным заявлениям Google, заключается в том, чтобы упростить поиск релевантной информации, поместив на первые позиции в поисковой выдаче наиболее качественные сайты [24]. В официальном блоге Google для вебмастеров даже опубликована статья, содержащая советы по улучшению сайтов с целью повышения их в топе поисковой системы после индексирования алгоритмом Panda [25]. Новый алгоритм, принцип работы которого был основан на столь большом количестве оцениваемых факторов, претерпел большое количество изменений и продолжает совершенствоваться. За два года существования Google Panda сменилось уже 24 обновления [26], каждое из которых активно обсуждается в SEO-сообществе, и 15 марта 2013 года было объявлено последнее, двадцать пятое обновление, после которого Google Panda, наряду с предыдущими алгоритмами, стал частью основного поискового алгоритма Google [27]. Таким образом, следует отметить, что совершенствование и доработка поискового механизма – это неотъемлемая часть политики Google с самого начала существования этой компании. Использование сложных и взаимосвязанных систем, при поисковой выдаче учитывающих большое количество самых разнообразных факторов, и практически полная независимость этих факторов от человеческого влияния делает Google привлекательным для рядового пользователя – совокупность работы множества схем в рамках единого поискового алгоритма на выходе дает наиболее релевантный результат.
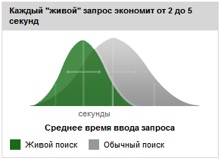
Некоторые особенности интерфейса и специфические компоненты поисковой системы Google Разобрав технические характеристики, рассмотрим и другие особенности поисковика Google – в этом подразделе речь пойдет о деталях интерфейса и специфических особенностях данного сервиса, с которыми пользователи непосредственно сталкиваются в процессе поиска информации в Сети. Цель этих компонентов – оптимизация аспектов поискового процесса, от скорости получения результатов до их упорядочивания. Большинство из этих инструментов являются отличительными для Google и либо не встречаются больше нигде, либо были переняты другими поисковиками позже. Одной из самых известных «визитных карточек» подобного рода для Google стала кнопка «Мне повезет» (англ. I’m feeling lucky!), расположенная рядом с кнопкой поиска на стартовой странице поисковой системы. Предназначение этой кнопки заключается в следующем – по щелчке на нее пользователь немедленно перенаправдяется на наиболее релевантный его запросу сайт, минуя окно результатов поиска, а следовательно – и выводящуюся на него рекламу. Как было сказано в самом Google, «функция "Мне повезёт!" позволяет тратить меньше времени на поиск и больше на чтение страниц» [28]. С этой кнопкой, введенной Google в 1998 году, связаны даже курьезные ситуации. Так, несмотря на то, что этой функцией поисковой системы практически никто не пользуется (94% отрицательных ответов против 6% положительных по данным опроса, проведенного на популярном сайте Habrahabr.ru[29]), разработчики Google долгое время отказывались убирать эту кнопку, хотя отсутствие рекламы при ее использовании даже одним процентом пользователей поисковика ежегодно обходился компании в 110 млн. долларов [30]. Причиной для этого стало то, что при попытке убрать кнопку терялся привычный вид сайта, что вызывало негодование пользователей. По словам вице-президента компании Мариссы Мейер, «Без элемента риска и игры поисковик стал бы слишком сухим, корпоративным и больше напоминал бы инструмент для зарабатывания денег» [31]. Тем не менее, кнопка «Мне повезет!», наряду со своей функциональностью, может таить в себе также опасность: так, например, результаты, на которые выполняет переадресацию эта функция, часто используются злоумышленниками для распространения спама и вирусов[32]. Хотя эта кнопка все еще доступна на стартовой странице русской версии поисковика, существует информация о том, что с учетом нововведений Google проводит редизайн сайта, в ходе которого функция «Мне повезет!» исчезнет из интерфейса [33]. По сообщению информационного интернет-портала Techi.com, изменения затронули финскую версию Google[34]. Сама администрация Google эту ситуацию никак не прокомментировала[58], но, предположительно, исчезновение функции, более десяти лет остававшейся неизменной, объясняется развитием поисковой системы и появлением в Google новых средств, вытеснивших старые. В частности, кнопка «Мне повезет» бесполезна в связке с другой функцией Google – так называемым «живым поиском» (англ. instant search или Google Instant), запущенным 9 сентября 2010 года. Хотя живой поиск и не стал инновацией – до Google эксперименты по внедрению подобной функции проводились другим поисковиком, Yahoo, - именно Google стал первым сервисом, внедрившим живой поиск и таким образом донесшим его идею до массового сознания [35]. При использовании Instant Search Google откликается на поисковые запросы непосредственно во время их ввода, причем результат корректируется по мере того, как пользователь вводит слова запроса одно за другим. Google объясняет введение живого поиска стремлением сократить затраты времени при поиске информации в Интернете. «Главное отличие Живого поиска от обычного заключается в том, что теперь вы получаете нужную информацию гораздо быстрее, так как необязательно вводить весь запрос и даже нажимать Enter. Кроме того, в Живом поиске вы видите результаты прямо при вводе текста. Таким образом, вы можете тут же изменять запрос, пока не найдете именно то, что вам нужно. Со временем, наверное, даже сложно будет представить себе, что когда-то поиск мог быть другим,» - значится в описании живого поиска на самом сайте Google[36]. Здесь же приведена диаграмма, иллюстрирующая преимущество Instant Search перед обычным поиском, и некоторые статистические данные:
Так, например, значится, что между нажатиями клавиш про формулировании запроса проходит около 300 миллисекунд, при этом взгляд на результаты запроса занимает в 10 раз меньше времени [36]. Следовательно, основная задача Google Search – увеличение скорости и оперативности поиска информации. Внедрение Google живого поиска стоило немалых затрат. Для реализации Google Instant пришлось решить целый ряд задач, включая повышение эффективности работы с кэшем и оптимизацию алгоритма JavaScript, отвечающего за обновление страницы. В общей сложности было использовано 15 новых технологий [37]. Однако живой поиск Google был воспринят неоднозначно. Несмотря на то, что скорость поиска информации действительно возросла, для рекламодателей и поисковых оптимизаторов в Интернете внедрение Instant Search будет означать необходимость полностью перестраивать свое поведение в Сети с учетом того, что с распространением живого поиска предпочтение пользователей будет отдаваться более коротким поисковым запросам [38]. Нет недостатка и в критике Instant Search – в Сети неоднократно были высказаны мнения о том, что живой поиск – это лишь «модная тенденция». Так, Андрей Иванов, ведущий специалист компании «Ашманов и Партнеры», известной за разработку программного приложения к браузеру Mozilla Firefox «A&P Search Tools», охарактеризовал живой поиск так: «Живой поиск сильно напрягает зрение, пользоваться им попросту неудобно [35]». Бытует и мнение о том, что Google Instant Search – это лишь украшение, не добавляющее сайту функциональности, и что Google следует вместо разработки подобных дополнений заняться дальнейшим совершенствованием алгоритма поиска[39]. Тем не менее, несмотря на противоречивые мнения, имеет смысл утверждать, что новая функция прижилась и даже обрела свою популярность. Подтверждением тому служит тот факт, что вслед за Google живой поиск появился на таких крупных сервисах, как всемирная социальная сеть Facebook (и ее аналог «ВКонтакте») и крупнейший интернет-магазин музыки Apple iTunes [35]. Кроме того, аналог Instant Search ввела другая известная поисковая система – Yahoo! [40]; также это нововведение ожидается для поисковика Bing от Microsoft [41]. Аналоги Instant Search реализованы даже вне связи с Интернетом: так, операционная система Windows начиная с версии Windows 7 позволяет производить такой поиск применительно ко всем файлам на компьютере, а встроенный в нее проигрыватель Windows Media Player таким образом обеспечивает поиск музыкальных композиций в фонотеке. Принцип работы Instant Search заключается в использовании AJAX [42] – так называемого асинхронного языка Java. Эта технология позволяет обеспечивать динамическое обновление содержимого тех или иных компонентов сайта без перезагрузки непосредственно страницы[43]. Об AJAX и его роли в сервисах Google речь в данной работе еще пойдет, более того – использование AJAX в Instant Search не является самым важным примером применения этой технологии в рамках Google. Но уже сейчас следует упомянуть, что использование AJAX делает сервисы Google сервисами нового поколения, неотъемлемой частью концепции Web 2.0 [44]. Понятием «живой поиск» также называют в чем-то схожий, но при этом достаточно сильно отличающийся от описанного выше сервис Google – поиск в реальном времени (англ. realtime search). Торговое название этого сервиса – «Google: Прямо сейчас» (англ. Google RealTime); он доступен по адресу http://www.google.ru/realtime. ; Основной целью поиска Google в реальном времени является информация, располагающаяся на сайтах с быстро обновляющимся содержимым. В первую очередь под такими сайтами следует понимать блоги и социальные сети, в частности – всемирно известные Twitter, Facebook и MySpace [45]. Всего официально заявлены в качестве поддерживаемых 5 сервисов:
«Новая функция будет полезна всем, кто хочет быть в курсе самых последних новостей. Раньше результаты поисковой выдачи не всегда носили динамический характер. Например, если вы ищете информацию о стихийных бедствиях или других новостях, которые стали актуальными за последние несколько дней, материал, содержащийся в новостных заметках, блог-постах или твитах, может оказаться самым релевантным. Кроме того, функция "Прямо сейчас" позволяет следить в режиме реального времени за тем, как развивается то или иное событие и как пользователи реагируют на него» - такую характеристику дал новой функции поисковика директор по продуктам Google Том Стоки [47]. Наряду с самой лентой результатов поиска сервисом предлагается несколько инструментов для упорядочивания найденных данных. Так, Google Latest Results позволяет определить для поиска параметр времени появления записи или поста, ее локации (то есть, можно читать последние известия как по всему миру, так и по любой конкретной точке земного шара) и языка (поддерживаются английский, русский, испанский и японский). Отдельной функцией этого сервиса является возможность вывода на экран всех комментариев к тому или иному посту в той или иной социальной сети[48] (команда «Обсуждения»). Сервис Google RealTime развивается с 7 декабря 2009 года [49], летом 2010 года этот сервис получил собственную страницу (http://www.google.ru/realtime). О популярности этого сервиса свидетельствует факт того, что аналогичные службы вслед за Google были реализованы множеством других поисковых систем, причем здесь к уже упомянутым Yahoo! и Bing добавляются отечественные гиганты Yandex и Mail.ru. Еще одной функцией, о которой необходимо здесь упомянуть, является голосовой поиск – еще один достаточно молодой сервис Google, призванный еще больше облегчить и ускорить поиск информации в Интернете. Тестирование сервиса началось в 2005 году. В 2007 году компания Google официально поддерживала телефонный номер 1-800-GOOG-411, позвонив по которому и сообщив свой запрос, можно было соединиться с любым искомым предприятием или заведением по всей территории США и Канады[50]. 12 ноября 2010 года этот сервис был свернут[50], но технология голосового поиска, используемая в нем, стала основой для новой функции поисковика Google, введенной в 2008 году в качестве приложения для мобильных устройств. В официальном блоге Google сообщается, что голосовой поиск может стать полезным в случае, если поисковая фраза слишком длинна или грамматически сложна, чтобы ее можно было быстро набрать на клавиатуре [51]. Кроме того, использовать голос в качестве средства общения с устройством и ввода поискового запроса намного удобнее, если поиск проводится в движении. «Что быстрее: произнести «синхрофазотрон» или набрать это слово на клавиатуре телефона?» - гласит один из рекламных слоганов этого сервиса. Голосовой поиск реализован для мобильных устройств на платформе SymbianOSv3 (смартфоны Nokia), Android 2.1 и выше, а также iPhone [52]. Среди поддерживаемых языков: английский, китайский, корейский, японский, французский, немецкий, итальянский, испанский, польский и чешский. Русский язык поддерживается голосовым поиском Google с 22 сентября 2010 года [52]. Работа над русским поиском Google заняла у разработчиков больше года. По словам одного из участников этой программы, Юджина (Евгения) Вайнштейна, часто было довольно сложно распознать схожие звуки, например «п» и «б». Дополнительную сложность накладывали диалекты и акцент[53]. Схема реализации голосового поиска объясняется уже в блоге Google: «Чтобы запустить Голосовой поиск… мы неделю за неделей собираем голосовые фрагменты, которые позволяют нам создать модели речи, обеспечивающие корректную работу сервиса. Мы просим носителей языка, отличающихся акцентами, возрастом и индивидуальными особенностями, произнести часто употребляемые фразы в самых разных акустических условиях, например, в ресторане, на улице или в машине. Для каждого языка мы также создаем словарь, содержащий более миллиона распознаваемых слов [53]». Функционирование голосового поиска на основе этого словаря обеспечивается разрабатываемым Google механизмом HTML speech input API[54]. Его принцип работы заключается в передаче записанного фрагмента голоса на так называемый языковой сервер Google, где запрос обрабатывается и преобразовывается в текстовую форму [55]. По состоянию на 2013 год механизм Voice Search уже доступен пользователям официального браузера Google – Chrome – в качестве отдельно устанавливаемого дополнения. Ожидается, что в течение ближайших 5 лет общее количество подключённых к Интернету мобильных устройств превысит подключённое число настольных ПК [53]. А при введении голосового поиска на ПК, утверждает в блоге Google Джоанна Райт, менеджер по разработке поисковых сервисов Google, поиск при помощи голоса станет воистину вездесущим, а сама идея голосового поиска станет значительно более привычной, вне зависимости от того, что конкретно является целью поиска [51]. В пользу популярности голосового поиска свидетельствует то, что, как и в случае с Google RealTime, аналогичные функции были внедрены в такие поисковики, как Yahoo! [56], Bing [56] и Yandex [57], причем последний запустил свой голосовой поиск чуть ли не одновременно с Google, но поддерживается лишь в некоторых его сервисах [57]. Рассмотрев все вышеприведенные особенности поисковой системы Google, можно сделать необходимые выводы. Google является динамически развивающимся поисковым сервисом, находящемся в постоянном процессе совершенствования своих алгоритмов работы и дополнительных функций, облегчающих поиск. При этом, если поисковые боты Google не отличаются по принципу своей работы от аналогичных программ, работающих на других поисковых системах, то алгоритмы поиска здесь претерпевают постоянные изменения и находятся в непрерывном процессе модернизации. Основанный на технологии BackRub, которой разработчики Google занимались еще в Стэнфордском университете, алгоритм PageRank является важным фактором, определяющим высокую релевантность результатов поиска Google. Кроме того, немаловажен факт того, что PageRank в связке с другими, более поздними поисковыми алгоритмами Google практически исключает участие в процессе индексирования ссылок и формирования результатов поиска человеческого фактора, что делает невозможной, в частности, продажу лучших в списке за деньги или так называемые «черные» методы продвижения сайтов. Дополнительный функционал поисковой системы Google также заслуживает упоминания. Живой поиск Google стал одним из первых сервисов, в которых была реализована технология динамически обновляющегося содержимого (AJAX) и язык JavaScript, использование которого упрощает работу с системой и сокращает время, необходимое на формирование запросов и получение результатов. Кроме того, Google принадлежит первенство во введении такой функции, как голосовой поиск. Многие технологии, реализованные в поисковой системе Google, в дальнейшем были заимствованы не только другими поисковыми системами, но и разработчиками программного обеспечения, лишь косвенно связанного с Интернетом вообще.
Список использованной литературы
________________________ © Брень Дмитрий Дмитриевич |
|